
Apache Kafka: an Essential Overview
Written by Clifford
To use an old term to describe something relatively new, Apache Kafka is messaging middleware. It is designed to send data from one server to another in a fault-tolerant, high-capacity way and, depending on the configuration, verify the receipt of sent data. In performance tests it has been shown to be able to do two million writes per second. In addition to being software, Kafka is also a protocol, like TCP. In other words, it operates at the transport layer of the OSI model. You can think of it as an extremely high-capacity syslog.
Kafka was written by LinkedIn and is now an open source Apache product. They wrote it in Scala. LinkedIn and other companies use Kafka to read data feeds and organize them into topics.
You can think of it as a replacement for any kind of messaging tool, like ActiveMQ, as it has the same publish-subscribe concepts. It is widely used today, because it scales almost without limit and is highly fault-tolerant. As shown below, it is often used with other open source tools that are likewise very popular.
The Linux system administrator could use Spark, for example, as a replacement for any kind of log collection (aggregator) platform. It sends its output on a socket just like syslog, using its own TCP protocol. So it would easily work as a syslog replacement. Since you are probably using syslog for log collection, you have a good excuse to install Kafka so that you can learn the product. Then you can figure out how it would fit with your other platform tools.
You can also output Kafka data to Hadoop or a data warehouse for analysis and reporting. Lots of companies, like Pinterest, use Kafka for processing streams. Those are, for example, webserver clickstreams, meaning data keeps coming and never stops (unlike a file that you open and close).
Later in this post we give examples of products that work with Kafka. That is its real value: connecting it to something else.
Kafka Concepts
First, here are Kafka’s basic concepts, illustrated by the graphic below from Hortonworks:
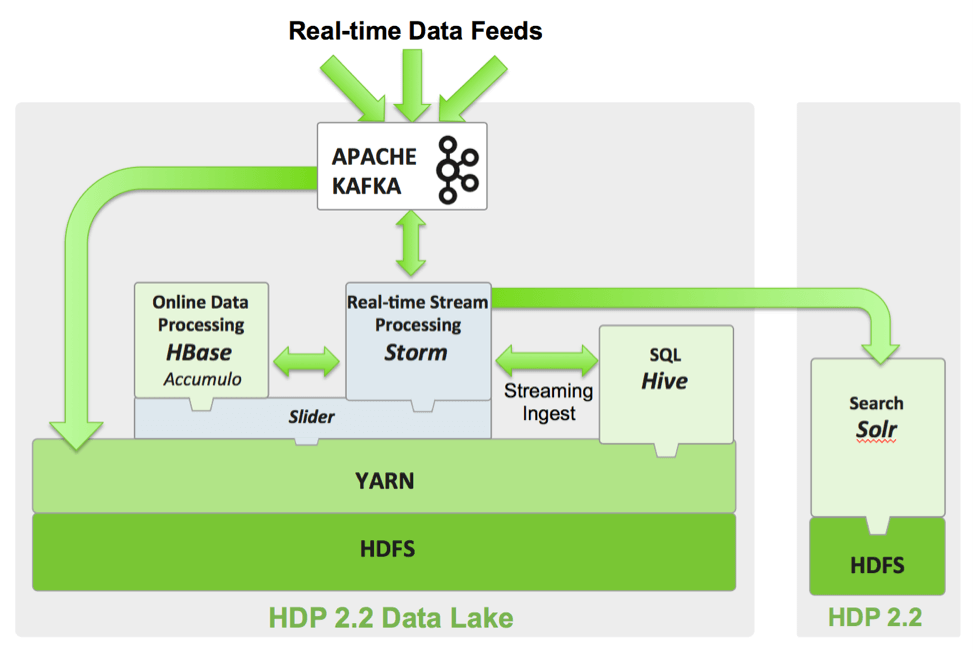
- Producers – consume the data feed and send it to Kafka for distribution to consumers.
- Consumers – applications that subscribe to topics; for example, a custom application or any of the products listed at the bottom of this post.
- Brokers – workers that take data from the producers and send it to the consumers. They handle replication as well.
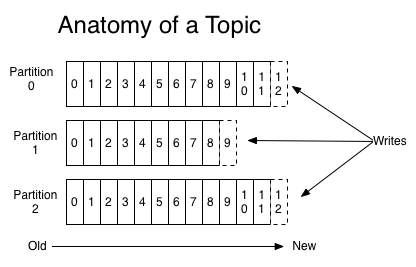
- Partitions – the physical divisions of a topic, as shown in the graphic below. They are used for redundancy as partitions are spread over different storage servers.
![]()
- Topics – categories for messages. They could be something like “apachelogs” or “clickstream”.
- Zookeeper – you start this before Kafka. Apache Zookeeper is used to start services in distributed systems. So it is not part of Kafka, but is needed by Kafka.
Create a Topic
These quick start instructions show you how to install Kafka, start Zookeeper, and start the server.
Then create a topic like this:
bin/kafka-topics.sh --create --zookeeper (server:port) --replication-factor 1 --partitions 1 --topic (topic name)
Publish and Consume a Message
Then you publish and consume a message as shown below. This simple example uses stdin and stdout to illustrate. You can also use tail to write data to it using Tail2Kafka. So you could, for example, use that to write Apache webserver logs to Kafka.
Publish:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
Consume:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
Kafka Clients
Clients are APIs that let you use Kafka with different programming languages like Python, Scala, Ruby, PHP, or Perl. The full list of clients is here.
For example, in this section of a Python program you can see that the developer has created Kafka client, consumer, and producer APIs that make it easy to work with those in Python.

Products used with Kafka
Below are some other open source products that have been integrated with Kafka. Most of the links below are links to the GitHub sites where you can download the integration software.
Storm
If you use Apache Storm, you usually use Kafka as a component of that. Storm is for processing streams. Everyone from Yahoo to Twitter uses it. Storm says it “…does for real-time processing what Hadoop did for batch processing.”
Storm produces its output in a graph. That does not mean a picture; it means a set of edges and nodes, which are the same as vectors and points. Graphs are used to model many kinds of data, like the Friends relationships between Facebook users. The Storm architecture is a kind of graph too, as shown in the illustration below.
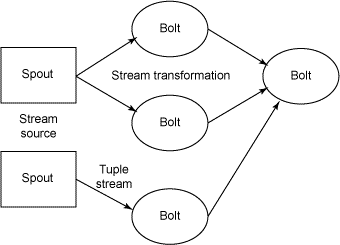
Bolts aggregate data and run join operations on that. Spouts are the source.
If you turn Storm off, you lose the data. That is because it is streaming data. Usually people do store streaming data, since its value is as a live feed used to run analytics.
Here is a graphic from Hortonworks showing how Kafka can sit in front of Storm and Hadoop. In this case, Storm writes its data to Hadoop.
Camus/Hadoop
Camus is another open source product from LinkedIn. It is used to dump Kafka data to Hadoop.
Logstash
Logstash is a tool for processing log events. But it’s more than that—it also facilitates Elasticsearch. Elasticsearch is the company behind three open source products: Elasticsearch, Logstash, and Kibana. Elasticsearch is called a “real-time distributed search and analytics engine.” It does full-text searches, aggregation, and analytics. Wikipedia, for example, uses it for searches.
Here is how to write data to a Kafka topic using Logstash:
$ bin/logstash -e "input { stdin {} } output { kafka { topic_id => 'logstash_logs' } }"
In the graphic below from Elasticsearch, each of the wooden logs with mustaches (that’s their logo) is collecting log events and pushing them to Kafka. Elasticsearch is one of the consumers as well. So is Apache Spark.
Spark is one of the consumers in the architecture above. Apache Spark is rapidly replacing MapReduce as a tool for reading data across Hadoop Distributed File Systems (HDFS). The main reason for this is that Spark does all of it in memory, thus running much faster.
So there you have a basic overview of Kafka. As I said above, you could probably use it in your infrastructure even if you are not doing any kind of analytics or even using Hadoop. Then you can see what it does and convince your management to use it elsewhere.

Leave a Comment